Otimizando o desempenho do Banco de Dados SQL: Dicas e técnicas


Em um mundo onde os dados são considerados o novo ouro, garantir que as operações relacionadas a eles sejam rápidas e eficientes é fundamental. O SQL, sendo uma linguagem padrão para gerenciar e consultar dados em bancos de dados relacionais, é onde muitas empresas frequentemente encontram gargalos de desempenho.
Neste artigo, abordaremos 20 dicas e técnicas essenciais para otimizar o desempenho de um banco de dados SQL.

1. Entendendo Planos de Execução
Antes de ajustar suas consultas, você precisa entender como elas funcionam. Os planos de execução descrevem a sequência de etapas utilizadas para acessar os dados. Ao analisar estes planos, pode-se identificar gargalos e otimizações potenciais.
O uso do EXPLAIN é um excelente começo:

Estudar os resultados pode revelar se um índice é utilizado, a ordem de junção de tabelas, e outras operações internas.
2. O Poder da Indexação
Índices são estruturas que podem acelerar drasticamente as consultas. Imagine procurar um nome em um livro de 1000 páginas que não tem índice; você teria que folhear página por página.

Ao criar índices apropriados, o servidor pode encontrar os registros necessários rapidamente. Porém, a manutenção de índices tem um custo: cada inserção, atualização ou exclusão pode necessitar de uma atualização do índice.
3. Evitando o SELECT *
A tentação de usar o SELECT * para buscar todos os campos de uma tabela é compreensível, especialmente quando não se está certo de quais colunas são necessárias. No entanto, essa prática pode levar a consultas ineficientes, trazendo uma sobrecarga desnecessária para o banco de dados. Ao recuperar informações excessivas, você pode enfrentar atrasos no tempo de resposta e uma utilização elevada de recursos. É sempre recomendável especificar apenas as colunas essenciais para a operação em questão.

Ao ser criterioso sobre quais colunas buscar, você otimiza o desempenho do banco de dados e reduz o tráfego de dados, beneficiando a aplicação como um todo.
4. Usando JOINs Adequadamente
A capacidade de unir tabelas é uma das características mais valiosas e poderosas dos bancos de dados relacionais. No entanto, se mal utilizados, os JOINs podem ser um calcanhar de Aquiles para o desempenho da consulta. Ao combinar registros de duas ou mais tabelas, é crucial garantir que as colunas usadas na condição JOIN estejam devidamente indexadas, evitando varreduras completas de tabela.

Além disso, a compreensão do propósito de diferentes tipos de JOINs (INNER, LEFT, RIGHT, etc.) é vital. Optar pelo tipo de JOIN mais específico para sua necessidade não apenas tornará sua consulta mais clara, mas também ajudará o servidor a processar menos registros, otimizando o desempenho geral da consulta.
5. Limitando Resultados
É comum querer ver apenas um subconjunto dos registros. Usar a cláusula LIMIT pode restringir o número de registros retornados, economizando tempo e recursos.

6. Consultas Parametrizadas
Consultas parametrizadas são uma abordagem que permite aos desenvolvedores especificar parâmetros em vez de inserir diretamente valores nas consultas SQL.
Esta prática traz uma camada significativa de segurança, pois ajuda a prevenir ataques de injeção de SQL, uma das vulnerabilidades mais comuns em aplicações web. Além de serem mais seguras, essas consultas também oferecem vantagens de desempenho. Quando se utiliza uma consulta parametrizada, o servidor pode reconhecer e otimizar a estrutura da consulta mesmo quando os valores dos parâmetros mudam, o que pode levar a tempos de execução mais rápidos e consistentes.

7. Normalização de Dados
A normalização é um conceito fundamental no design de bancos de dados relacionais. Seu objetivo é minimizar a duplicidade e dependência, organizando dados de forma lógica e eficiente. Através deste processo, os dados são organizados em tabelas separadas, baseadas em temas ou conceitos, e são estabelecidas relações entre essas tabelas usando chaves.
Isso não só reduz a redundância, como também facilita a manutenção, uma vez que as atualizações ou alterações em um conjunto de dados não requerem múltiplas alterações em diferentes lugares. A longo prazo, ter um banco de dados bem normalizado facilita consultas, reduz erros e garante a integridade dos dados.
8. Usando Vistas
Vistas são consultas armazenadas que podem encapsular lógica complexa ou junções frequentemente utilizadas. Ao invés de reescrever a mesma lógica em várias partes do seu aplicativo, você pode referenciar uma vista.

9. Otimizando Subconsultas
Subconsultas são consultas aninhadas dentro de outras consultas. Embora poderosas, elas podem ser mais lentas do que alternativas equivalentes, como JOINS.
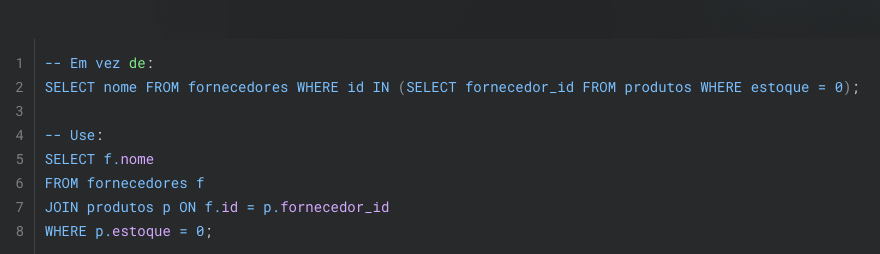
10. Evitando Funções em Condições WHERE
Aplicar funções a colunas em cláusulas WHERE pode ser custoso e geralmente impede o uso de índices.

11. Particionamento de Tabelas
Tabelas grandes podem ser divididas em partes menores, ou partições, baseadas em critérios específicos, como faixa de datas, IDs ou geolocalização. Ao dividir eficientemente as tabelas, o desempenho das consultas pode ser melhorado, já que o servidor pode focar apenas nas partições relevantes, reduzindo o volume de dados a serem escaneados. Esse método é especialmente benéfico para bancos de dados com grandes volumes de transações ou dados históricos.
12. Utilizando Caching
O uso de sistemas de caching, como Redis ou Memcached, ajuda a aliviar a carga sobre o banco de dados. Estas ferramentas armazenam dados frequentemente acessados na memória, o que resulta em tempos de resposta mais rápidos para consultas recorrentes. Ao reduzir a necessidade de consultar diretamente o banco de dados para cada pedido, a latência e o desgaste geral do sistema diminuem significativamente.
13. Manutenção Regular
Manter um banco de dados é semelhante a cuidar de um veículo: ambos requerem atenção regular para funcionar de forma otimizada. A fragmentação pode ocorrer com o uso contínuo, e atividades como a otimização de tabelas, a reconstrução de índices e a remoção de dados obsoletos são essenciais para manter a integridade e a eficiência do sistema. Agendar e automatizar essas tarefas pode assegurar um desempenho consistente a longo prazo.
14. Monitoramento e Análise
Utilizar ferramentas de monitoramento, como o Prometheus ou o Zabbix, é fundamental para manter a saúde do banco de dados. Essas ferramentas podem alertar sobre consultas ineficientes, bloqueios prolongados, ou até mesmo falhas de hardware. Ter insights em tempo real sobre o desempenho do sistema permite uma resposta rápida a potenciais problemas, garantindo uma operação suave e reduzindo tempos de inatividade.
15. Replicação e Balanceamento de Carga
Em ambientes com alta demanda, a replicação de banco de dados pode ser uma solução vital. Ter múltiplas cópias do banco de dados não só ajuda na distribuição da carga de leitura, mas também oferece uma camada adicional de redundância. Balanceadores de carga, como o HAProxy ou o Nginx, podem direcionar o tráfego de forma inteligente entre essas réplicas, assegurando que nenhuma instância seja sobrecarregada.
16. Considerando NoSQL
Para projetos que lidam com dados não-relacionais, volumosos, ou que precisam de alta escalabilidade, bancos de dados NoSQL, como MongoDB, Cassandra ou Couchbase, podem ser a resposta. Essas soluções oferecem flexibilidade na estrutura de dados, distribuição horizontal e modelos de consistência adaptáveis, tornando-as ideais para certas aplicações modernas, como big data ou aplicativos móveis.
17. Backup e recuperação
Embora isso não seja diretamente uma otimização de desempenho, garantir que você tenha backups regulares e uma estratégia de recuperação é vital. Problemas de desempenho podem ocorrer, e ter um backup recente pode ser um salva-vidas.
18. Aproveitando Stored Procedures
Stored Procedures são blocos de comandos SQL que são armazenados no banco de dados e podem ser invocados quando necessários. Como já estão compilados, eles podem ser executados mais rapidamente do que múltiplas consultas enviadas individualmente.

Com isso, você pode simplesmente chamar BuscarClientesVIP em vez de reescrever a consulta várias vezes.
19. Atualização de Versão
Muitas vezes, simplesmente manter seu SGBD (Sistema de Gerenciamento de Banco de Dados) atualizado pode trazer melhorias de desempenho. Os desenvolvedores desses sistemas frequentemente lançam atualizações que abordam problemas de performance, adicionam otimizações e introduzem novas funcionalidades que podem ajudar na eficiência das operações.
Certifique-se de sempre verificar as notas de lançamento e testar a nova versão em um ambiente controlado antes de atualizar o ambiente de produção.
20. Evitando Triggers Ineficientes
Triggers são procedimentos automáticos que são executados em resposta a determinados eventos no banco de dados, como inserções, atualizações ou exclusões. Embora sejam úteis, eles podem ser uma fonte oculta de lentidão, especialmente se executarem operações complexas ou não otimizadas.

Se você notar lentidão ao inserir na tabela vendas, a causa pode ser o trigger. Sempre revise e otimize os triggers para garantir que eles não estejam afetando adversamente a performance.

Conclusão
Otimizar um banco de dados SQL é uma combinação de arte e ciência, exigindo uma compreensão profunda das consultas, da estrutura do banco de dados e das características específicas do sistema de gerenciamento de banco de dados utilizado.
Espero que, com as dicas acima, você esteja melhor equipado para enfrentar os desafios de desempenho do banco de dados SQL e melhorar significativamente a eficiência e a resposta do seu sistema.
A Revelo Content Network acolhe todas as raças, etnias, nacionalidades, credos, gêneros, orientações, pontos de vista e ideologias, desde que promovam diversidade, equidade, inclusão e crescimento na carreira dos profissionais de tecnologia.