O uso de Inteligência Artificial para classificação com técnica de Árvore de Decisão


Neste tutorial vamos aprender como a classificação através da técnica de Árvore de Decisão pode construir e também aprimorar medidas de seleção de atributos de uma base de dados usando o pacote Python Scikit-learn.
Suponto que você é responsável pelo setor de Marketing e almeja um conjunto de clientes com maior probabilidade de adquirir seu produto. Dessa forma, você pode otimizar seu orçamento de publicidade ao identificar seu público-alvo. Como gestor de empréstimos, é necessário identificar solicitações de empréstimo de alto risco, visando reduzir a taxa de inadimplência.
Esse procedimento de categorização dos clientes em potenciais ou não potenciais, ou de classificação das solicitações de empréstimo como seguras ou arriscadas, é conhecido como desafio de classificação.
A classificação é um processo composto por duas fases: uma fase de aprendizado e uma fase de previsão. Na fase de aprendizado, o modelo é desenvolvido com base nos dados de treinamento fornecidos. Na fase de previsão, o modelo é aplicado para estimar as respostas com base nos dados fornecidos.
Uma árvore de decisão figura entre os algoritmos de classificação mais simples e populares, utilizados para compreender e interpretar dados. Esse algoritmo pode ser empregado tanto em problemas de classificação quanto em problemas de regressão.

Como funciona o algoritmo da Árvore de Decisão (AD)
Dentre os algoritmos de aprendizado supervisionado, a AD pode ser considerado um dos mais simples e descrito como uma coleção de regras do tipo SE...ENTÃO (QUINLAN, 1986; MITCHELL, 2010).
Por causa disso, as ADs têm sido largamente empregadas em tarefas de classificação, como sendo um caminho eficaz na construção de classificadores que predizem classes com base nos valores dos atributos que expõem os modelos. Desta forma, elas podem ser empregues em diversas aplicações como diagnósticos médicos e análise de risco em créditos, entre outros exemplos.
A chave para o sucesso de um algoritmo AD é como gerar a árvore, ou seja, como escolher os atributos mais significativos para gerar as regras e quais regras podem ser descartadas da árvore (MITCHELL, T. M. 2010). Um bom conceito está na geração da AD baseado na relevância das suas particularidades, ou seja, dos seus atributos.
Desta maneira, o atributo de mais significativo será o que está na raiz da árvore. Sendo assim, um menor número de regras poderá ser empregado para a solução de um determinado problema. De acordo com Araújo et al. (2018), em fator de que as Ads são construídas com baseada na importância de cada atributo, nem sempre elas se valem de todos os atributos que refletem um padrão para geração do conjunto de regras, trazendo o benefício de reduzir o tempo computacional nas tarefas de classificação.
Entre os algoritmos de AD estão ID3 (QUINLAN, 1986; MITCHELL, 2010), C4.5 (QUINLAN, 1993) e CART (BRAMER, 2007), sendo o primeiro dos mais básicos. O algoritmo C4.5 constrói AD a partir de um conjunto de dados da mesma forma que o algoritmo ID3, usando o conceito de entropia e ganho de informação para definir a importância dos atributos, conforme apresentado nas equações 1 e 2.
Em cada nó da árvore, o algoritmo C4.5 escolhe o atributo que melhor particiona o conjunto de amostras em subconjuntos, tendendo a uma categoria ou outra. O atributo com maior ganho de informação normalizado é escolhido para tomar a decisão (QUINLAN, 1993).
Para realizar o cálculo do ganho de informação, primeiro obtém-se a entropia. A entropia de um conjunto pode ser definida como sendo o grau de pureza desse conjunto. Dado um conjunto de entrada S que pode ter n classes distintas, a entropia de S é dada por:
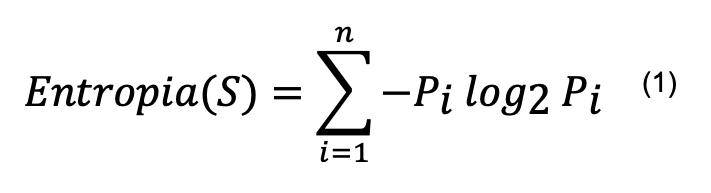
Onde Pi é a proporção de dados em S que pertencem à classe i.
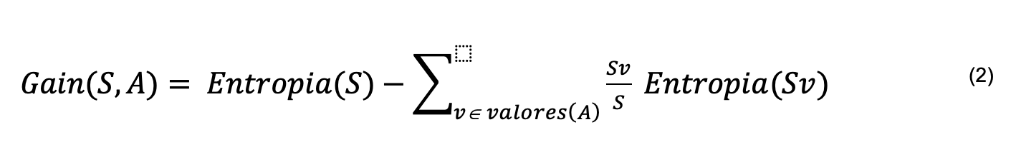
V é um elemento dos valores que o atributo A pode assumir e Sv é o subconjunto de S formado pelos dados em que A=v.
Este método de categorização pode ser facilmente compreendido por meio do seguinte exemplo: Suponhamos que o objetivo é determinar se irei praticar Tênis. Para isso, é necessário levar em consideração certos elementos do ambiente, como a Aparência do Céu, a Temperatura, a Umidade e o Vento. Cada um desses atributos possui diversas opções.
Por exemplo, para a temperatura, pode ser considerado Ameno, Fresco ou Quente. A decisão de Sim (praticar tênis) ou Não (não praticar tênis) é o resultado da categorização. Para criar a Estrutura de Decisão para a prática do Tênis, são considerados exemplos (dias) anteriores. A tabela 1 a seguir demonstra o exemplo citado.
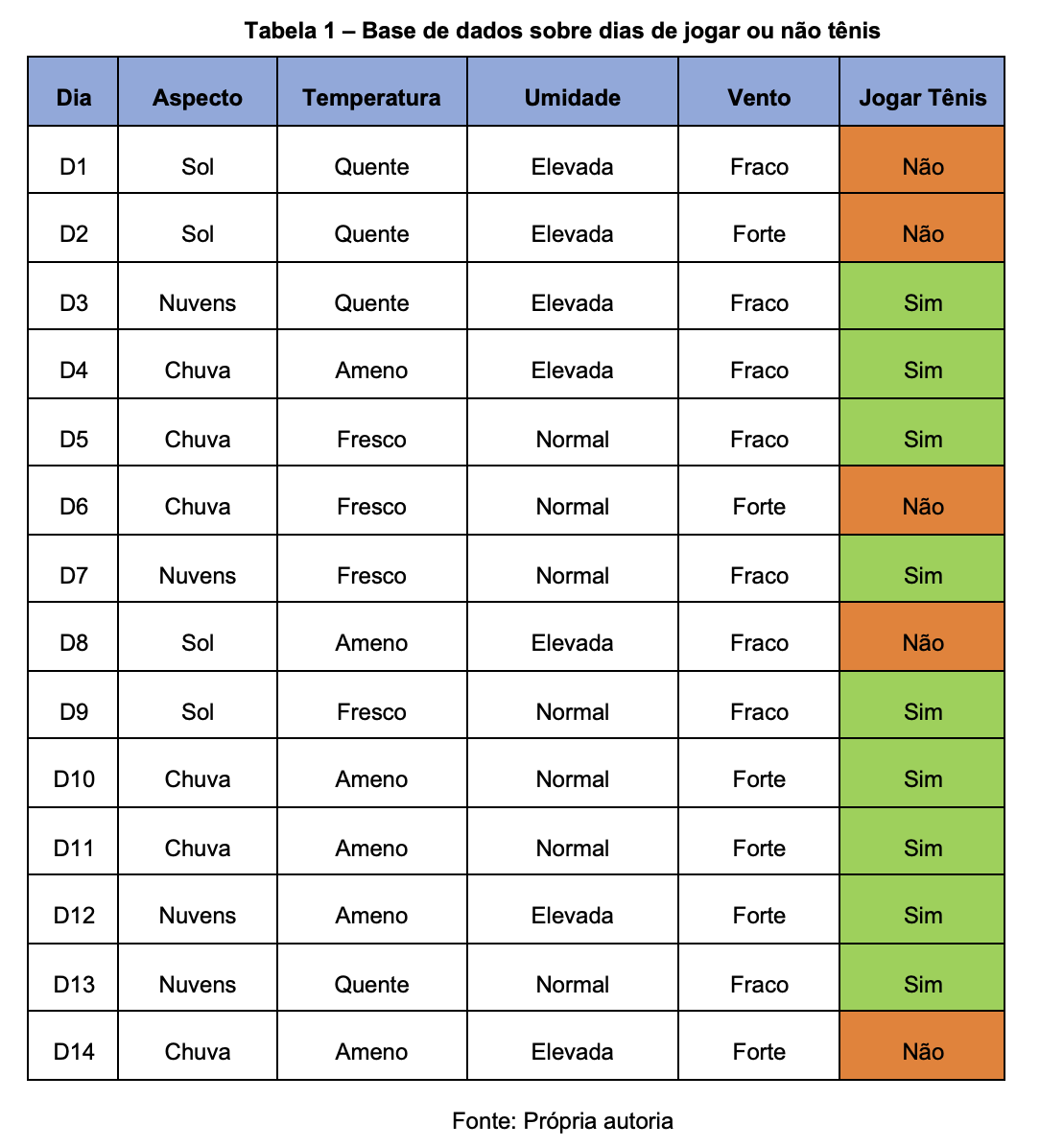
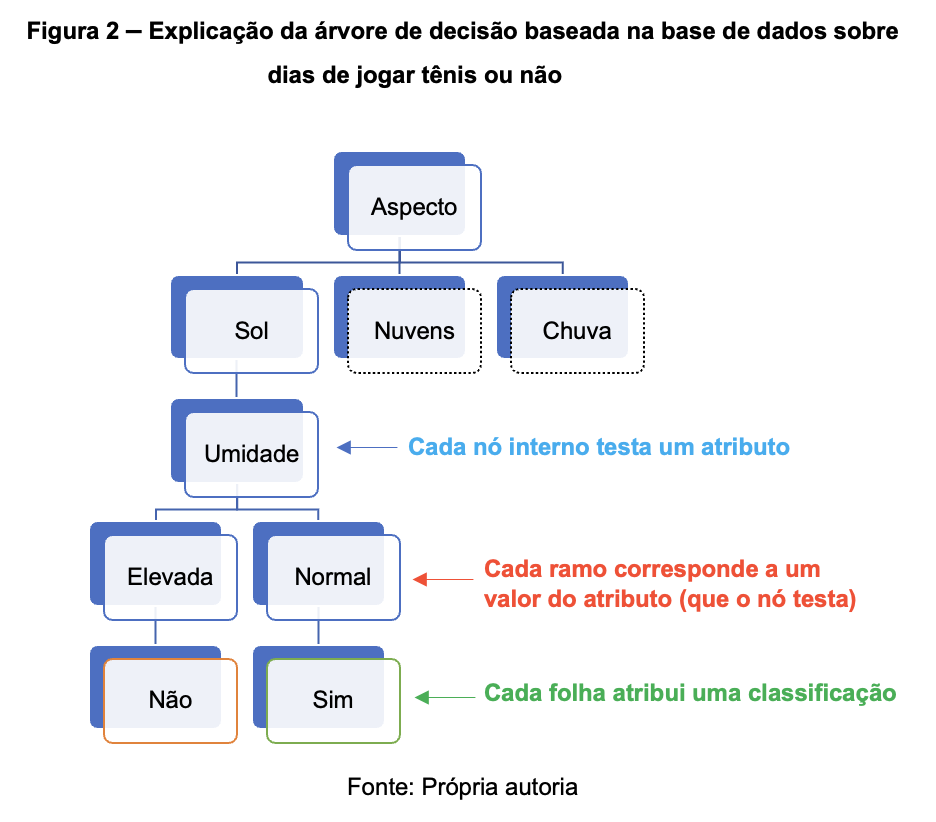
Através destes exemplos é possível construir a seguinte árvore de decisão:
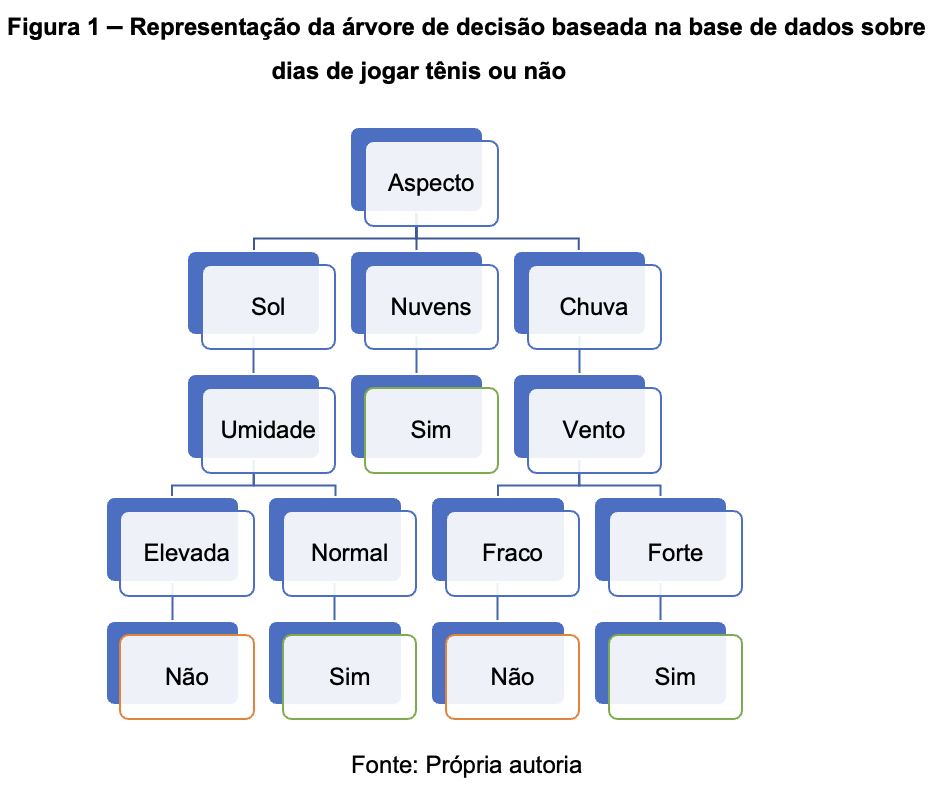
A relação entre os elementos da árvore (nós e folhas) e os atributos (valores e classificações), pode ser entendida na imagem a seguir:
Codificação
Para começar a construção do nosso classificador de árvore de decisão, iremos utilizar o Scikit-learn como base importando algumas bibliotecas necessárias.

Baixando a base de dados para realização da classificação
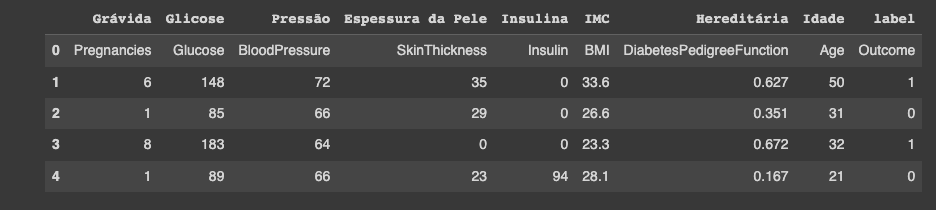
Primeiramente fazemos o download do conjunto de dados Pima Indian Diabetes necessário para usar a função de read CSV dos pandas (pd.read_csv). A base de dados pode ser baixada no site da Kaggle.
Sobre a base de dados
Contexto
Este conjunto de dados é originalmente do Instituto Nacional de Diabetes e Doenças Digestivas e Renais. O objetivo do conjunto de dados é prever de forma diagnóstica se um paciente tem ou não diabetes, com base em certas medidas de diagnóstico incluídas no conjunto de dados.
Várias restrições foram colocadas na seleção dessas instâncias de um banco de dados maior. Em particular, todos os pacientes aqui são mulheres com pelo menos 21 anos de idade, descendentes dos índios Pima.
Conteúdo
Os conjuntos de dados consistem em várias variáveis preditivas médicas e uma variável de resultado. As variáveis preditoras incluem o número de gestações que a paciente teve, seu IMC, nível de insulina, idade e assim por diante.





Como otimizar o Desempenho da Árvore de Decisão
- Criterion: Permite-nos usar a medida de seleção de atributo diferente como “gini” para o índice de Gini e “entropia” para o ganho de informação.
- Splitter: Permite-nos escolher a estratégia de divisão como "best" ou "random" que faz a melhor divisão de maneira aleatória.
- Max_depth: Permite-nos escolher a profundidade máxima da árvore de decisão.


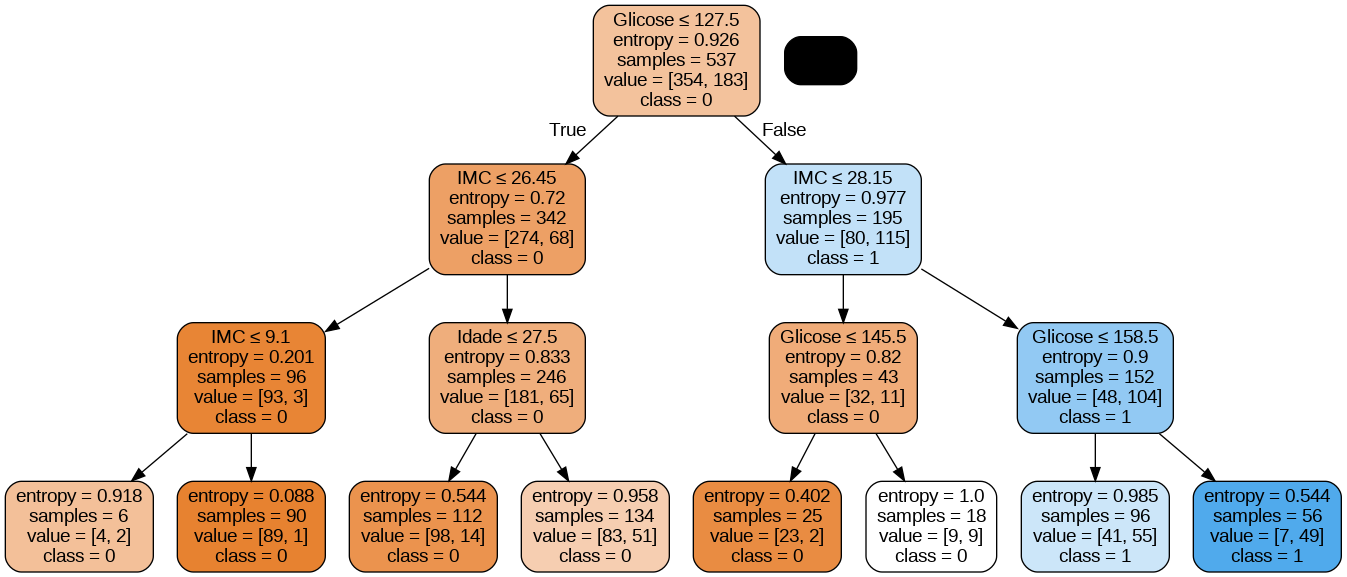
Acurácia: 0.7705627705627706.
A taxa de acerto para a classificação obtida foi de 77,05%, a qual é considerada uma boa precisão. Mas podemos melhorar essa taxa ajustando os parâmetros no algoritmo da nossa árvore de decisão.
Imprimindo a Árvores de Decisão
É possível utilizar a função export_graphviz do Scikit-learn para mostrar a árvore de decisão usando o Colab ou Jupyter Notebook. Para representar a árvore, é necessário instalar também o graphviz e o pydotplus, utilizando os comandos abaixo.

A função export_graphviz transforma o classificador da árvore de decisão em um arquivo de ponto e o pydotplus converte esse arquivo de ponto em png ou formato visível no Colab ou Jupyter.
Pontos positivos no uso de árvores de decisão
- As árvores de decisão são fáceis de serem visualizadas e interpretadas por qualquer pessoa.
- Seu tempo de pré-processamento é bem menor do que em outros algoritmos devido a não necessidade de normalizar dos dados.
- Ele pode ser usado para engenharia de recursos, como prever valores ausentes, adequado para seleção de variáveis.
- A árvore de decisão não tem suposições sobre distribuição devido à natureza não paramétrica do algoritmo.
Pontos negativos no uso de árvores de decisão
- Este algoritmo é sensível a dados com ruídos.
- Variações ainda que pequenas nos dados podem resultar em uma árvore de decisão diferente.
- As árvores de decisão são tendenciosas com o conjunto de dados sem uma correta mineração prévia dos dados.
- Árvores muito profundas e complexas podem se tornar difíceis de interpretar e suscetíveis a erros devido a variações nos dados.

Conclusão
Espero que você tenha gostado do artigo sobre esta técnica de inteligência artificial. Em próximos artigos podemos falar sobre técnicas de minteração de dados e o uso de outros algoritmos de inteligência artificial e seu uso no dia a dia das empresas.
Referências
- BRAMER, M. Principles of data mining. Springer, London. (2007).
- MITCHELL, T. M. Machine Learning. New York: McGraw-Hill. (2010).
- QUINLAN, J. R. Induction of decision trees. Machine Learning, 1(1):81-106. (1986).
- UCI Machine Learning, Pima Indians Diabetes Database. Predict the onset of diabetes based on diagnostic measures. Kaggle, 2018. Disponível em: https://www.kaggle.com/datasets/uciml/pima-indians-diabetes-database. Acesso em: 23 de jun. de 2023.
A Revelo Content Network acolhe todas as raças, etnias, nacionalidades, credos, gêneros, orientações, pontos de vista e ideologias, desde que promovam diversidade, equidade, inclusão e crescimento na carreira dos profissionais de tecnologia.Jueves, 5 de enero