Implantando infraestrutura como código na AWS


A infraestrutura como código é cada vez mais procurada. Independentemente de você ser um Cloud Architect ou Cloud Developer, as empresas exigem que você tenha experiência na implantação de infraestrutura como código devido às diversas vantagens que isso representa.
Algumas vantagens do acima são:
- Reconstruir um serviço em nuvem: Quer você tenha seu ambiente de desenvolvimento e produção em diferentes regiões ou contas, você pode implantar seu serviço com alguns comandos.
- Verificar as configurações: Você poderá ver facilmente a configuração do seu serviço e, se necessário, alterá-la para reimplantá-lo.
- Provisionar sua implantação na nuvem: de forma simples e rápida, pois é a ferramenta responsável por fazer tudo.
- Alterar provedor: Muitas vezes é difícil migrar uma arquitetura de um provedor para outro. Ferramentas como Terraform ou Serverless Framework permitem uma migração fácil.
- Tempo: Implantar nossa infraestrutura como código é mais rápido do que implantá-la via console.

Existem diversas ferramentas que permitem trabalhar em toda a arquitetura que você precisa de forma fácil e simples, sem ter que usar o console ou dashboard do seu provedor. Vamos nos concentrar no Serverless Framework para implantar alguns serviços Amazon Web Services (AWS), como S3 Bucket, SQS e DynamoDB. Usaremos o Serverless Framework não apenas para implantar nossa infraestrutura como código, mas também para nossas permissões e funcionalidades, a fim de aproveitar a maioria dos recursos ou serviços oferecidos pela AWS.
O processo de instalação do Serverless Framework é simples: você pode usar a documentação oficial.
O arquivo serverless.yml procurará o Serverless Framework para saber o que implantar e qual é sua configuração. Para criá-lo podemos usar um template padrão, mas é recomendado fazer nosso arquivo do zero. Não é algo complexo, mas nos permitirá compreender plenamente o que estamos implantando. Este arquivo possui uma estrutura que devemos cumprir, que pode variar um pouco dependendo do que precisamos implantar, ou seja, infraestrutura, permissões ou funções.
Quando implantamos recursos com uma ferramenta, o CloudFormation cria buckets com o nome do serviço para salvar a configuração, estado, etc. Esses buckets são importantes para a implantação de nossos projetos.
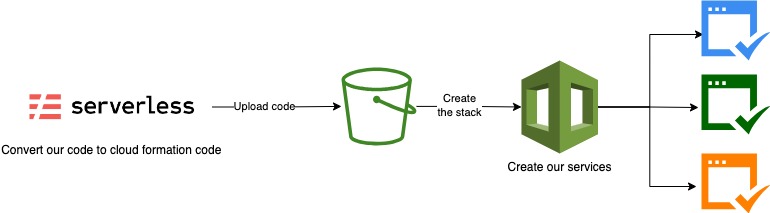
Estrutura do arquivo serverless.yml
Nome do projeto: service
O projeto service irá gerar um bucket S3, que será usado pelo CloudFormation para verificar a implantação anterior e compará-la com a implantação atual. Isto permite que elementos da nossa infraestrutura sejam adicionados, modificados ou removidos de forma eficiente.
Configuração do provedor
Na seção provider, configuraremos os detalhes do nosso provedor de serviços. Isso inclui o nome, o idioma e a versão (runtime), o estágio (stage) do nosso projeto e a região em que queremos que ele seja implantado.
Personalização de projetos
No bloco customizado temos a opção de configurar variáveis para diferentes ambientes. No código acima estabelecemos que a região onde queremos que nossa infraestrutura seja implantada será dinâmica e estará localizada em custom.config.dev/prod.my_region. Isso nos permite implantar em ambientes de desenvolvimento (dev) ou produção (prod) sem nos preocupar em alterar manualmente os valores das variáveis.
Início da infraestrutura
Na seção resources é onde escreveremos nossa infraestrutura. Entretanto, é uma boa prática separar nosso código em arquivos modulares.
Para fazer uso desses arquivos, devemos colocá-los no mesmo diretório do nosso arquivo serverless.yml e importá-los com a sintaxe ${file(filename.yml)}. Dado que resources é uma lista, devemos prefixar - o nome do nosso arquivo para incluí-lo corretamente.
# Nome do projeto
service: nome-do-meu-projeto-infra
# Configuração do provedor
provider:
name: aws
runtime: python3.8
stage: ${self:custom.stage, 'dev'}
region: ${self:custom.config.${self:custom.stage}.my_region}
# Personalização do projeto
custom:
stage: ${opt:stage, ‘dev’}
config:
dev:
account_id: ''
my_region: ${opt:region, 'us-east-2'}
prod:
account_id: ''
my_region: ${opt:region, 'us-east-1'}
Este pequeno exemplo contém apenas duas variáveis que podem mudar dentro custom: o id da conta e a região, mas isso não significa que não poderemos adicionar mais variáveis, que são, em sua maioria, aquelas que precisamos configurar separadamente.
# Início da infraestrutura ou recursos
resources:
- ${file(s3.yml)}
Na seção resources não usaremos mais arquivos YAML tradicionais, mas usaremos a sintaxe CloudFormation. Esta sintaxe é baseada no CamelCase, com algumas pequenas variações para adicionar elementos como rótulos.
Em nosso arquivo s3.yml teremos a possibilidade de criar vários buckets, mas é importante lembrar que não devemos alterar apenas o nome do bucket, mas também o identificador do recurso, referindo-se a como ele é nomeado dentro nosso projeto Serverless. É crucial que esses elementos tenham nomes exclusivos.
S3.yml
Resources:
S3Bucket:
Type: 'AWS::S3::Bucket'
DeletionPolicy: Delete
Properties:
BucketName: my-first-bucket
S3Bucket2:
Type: 'AWS::S3::Bucket'
DeletionPolicy: Delete
Properties:
BucketName: my-second-bucket
Com essas configurações, você poderá implantar dois buckets S3 na AWS de forma independente, independentemente da conta ou região em que estiver.
É importante considerar que os buckets no S3 são elementos globais, o que significa que seu Amazon Resource Name (ARN) não está associado a uma conta ou região específica. Portanto, você pode criá-los e acessá-los de qualquer conta ou região em que tenha acesso.
Se você deseja ter buckets diferentes para os ambientes de desenvolvimento (dev) e produção (prod), pode fazê-lo dinamizando o nome dos recursos e configurando-os na seção customizada. Dessa forma, você pode ajustar os nomes dos buckets de acordo com suas necessidades e requisitos específicos de cada ambiente.
Com essas considerações, você poderá ter a flexibilidade necessária para gerenciar adequadamente seus buckets S3 na AWS e adaptá-los de acordo com as necessidades de seu projeto e ambientes. Lembre-se sempre de seguir boas práticas de segurança e garantir que as permissões e políticas de acesso estejam configuradas corretamente para cada bucket de nuvem.
Custom refatorizado:
custom:
stage: ${opt:stage, ‘dev’}
config:
dev:
account_id: ''
my_region: ${opt:region, ‘us-east-2'}
my_first_bucket: my-first-dev-bucket
my_second_bucket: my-second-dev-bucket
prod:
account_id: ''
my_region: ${opt:region, 'us-east-1'}
my_first_bucket: prod-bucket-name-1
my_second_bucket: prod-bucket-name-2
Para aplicar essas mudanças devemos aplicar as variáveis dinâmicas ao nosso arquivo:
S3.yml:
Resources:
S3Bucket:
Type: 'AWS::S3::Bucket'
DeletionPolicy: Delete
Properties:
BucketName: ${self:custom.config.${self:custom.stage}.my_first_bucket}
S3Bucket2:
Type: 'AWS::S3::Bucket'
DeletionPolicy: Delete
Properties:
BucketName: ${self:custom.config.${self:custom.stage}.my_second_bucket}
Com isso estaríamos prontos para implantar buckets em dois ambientes de dev/prod diferentes sem a necessidade de alterar o código em nossos arquivos Yaml.
Comando para implantar nossos buckets
Ambiente dev:
serverless deploy
Ambiente prod:
serverless deploy —stage prod
Como resultado, serão criados dois buckets correspondentes aos ambientes de desenvolvimento (dev) e produção (prod). Neste caso, configuramos custom.stage para que dev seja o ambiente padrão, portanto não foi necessário indicar explicitamente o estágio no primeiro comando.

Nos próximos artigos, focaremos na implantação de permissões e funções. Por isso, é importante ficar atento à linha de atendimento. Além do nome do nosso projeto, contém a palavra infra para fazer referência ao nome do bucket. Um valor que será adicionado automaticamente pelo CloudFormation é o estágio, portanto encontraremos um bucket com o seguinte nome após realizar nossa implantação: my-infra-dev-project-name ou my-infra-dev-project-name prod.
Não devemos nos preocupar com o soft limit dos buckets (100) sempre que precisarmos de mais buckets, Podemos enviar um ticket para a AWS para aumentar esse limite sem aumentar o valor da fatura, pois a cobrança no S3 não é pela quantidade de buckets criados ou disponíveis.
O código mostrado neste artigo pode ser baixado neste seguinte repositório.
Seguindo as etapas detalhadas neste artigo, conseguimos implantar uma infraestrutura no Amazon Web Service (AWS). É importante ressaltar que cada recurso e serviço desta plataforma possui seu próprio esquema a ser criado. Em artigos futuros, me aprofundarei nesses esquemas e em suas aplicações para fornecer uma compreensão mais completa de como aproveitar ao máximo os recursos da AWS.
A Revelo Content Network acolhe todas as raças, etnias, nacionalidades, credos, gêneros, orientações, pontos de vista e ideologias, desde que promovam diversidade, equidade, inclusão e crescimento na carreira dos profissionais de tecnologia.