Criando seu primeiro modelo de IA: classificando mensagens de spam com Python


Hoje em dia, o fluxo constante de emails e mensagens de texto tornou a classificação de spam uma tarefa essencial nas nossas vidas digitais. Quem nunca recebeu spam na caixa de entrada?
Felizmente, a Inteligência Artificial (IA) e o Aprendizado de Máquina (Machine Learning) nos oferecem ferramentas poderosas para resolver esse problema. Neste artigo, orientarei você na criação de seu primeiro modelo de IA em Python para identificar e classificar mensagens como spam ou ham (não spam).

Conceitos básicos de IA e Aprendizado Automático
Antes de mergulharmos na criação do modelo, é importante compreender alguns conceitos-chave.
- A Inteligência Artificial tem como foco a criação de sistemas capazes de realizar tarefas que exigem inteligência humana, como o reconhecimento de padrões.
- O Machine Learning, por outro lado, é um ramo da IA que se concentra no desenvolvimento de algoritmos e modelos que podem aprender com os dados e tomar decisões com base nesses dados.
Obtendo dados de exemplo
Para construir nosso modelo de IA, precisamos de dados de treinamento. Você pode criar seu próprio conjunto de dados rotulando manualmente as mensagens como "spam" ou "ham", ou pode usar um conjunto de dados público. Neste exemplo, usaremos um conjunto de dados de amostra que preparei e que você pode encontrar em meu repositório do GitHub.
Carregar dados com Pandas
Usaremos a biblioteca Pandas em Python para carregar os dados do arquivo CSV. Certifique-se de ter o Pandas instalado com antecedência. Aqui está o código para carregar os dados e exibir as primeiras linhas do DataFrame:

O DataFrame do resultado conterá duas colunas: uma para os rótulos ("label") que indicam se a mensagem é spam ou ham, e outra para o conteúdo da mensagem ("message"). Esses dados são essenciais para treinar e avaliar nosso modelo de IA de classificação de spam.
Limpeza e pré-processamento de dados
Depois que nossos dados forem carregados, é importante realizar a limpeza e o pré-processamento adequados antes de usá-los para treinar nosso modelo de IA. Isso envolve a execução de diversas tarefas, como:
- Conversão para minúsculas: Isto é para garantir que letras maiúsculas e minúsculas não sejam tratadas como diferentes.
- Eliminação de Números: Em muitos casos, os números não são relevantes para a classificação de spam, por isso é comum excluí-los.
- Eliminação de sinais de pontuação: Os sinais de pontuação geralmente não fornecem informações úteis neste contexto, portanto podem ser removidos.
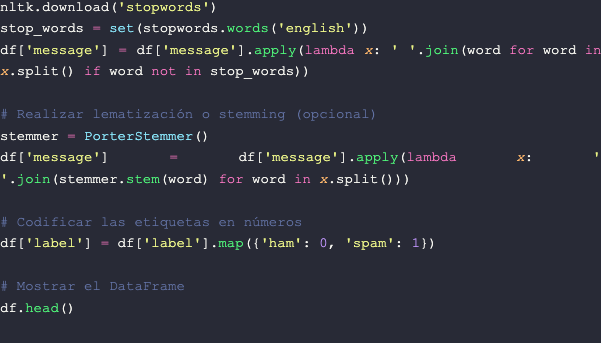
- Eliminação de palavras irrelevantes (Stop Words): Palavras comuns como “e”, “o”, “em” etc. geralmente não contribuem para a classificação e podem ser removidas.
- Lematização ou Stemming: Reduza as palavras à sua forma básica (lema) ou na sua raiz (stem) pode ajudar a reduzir a dimensionalidade do texto e melhorar a precisão do modelo.
- Codificação de etiqueta: Para fazer o modelo é necessário codificar as etiquetas em números. Podemos atribuir o valor 0 para ham e 1 para spam.
Aqui está um exemplo de como você poderia realizar algumas dessas tarefas em Python usando a biblioteca NLTK. Certifique-se de tê-lo instalado com antecedência:

Dividindo os dados em conjuntos de treinamento e validação
Depois de limparmos e pré-processarmos nossos dados, é essencial dividi-los em conjuntos de treinamento e validação. Isso nos permitirá treinar nosso modelo de IA e avaliar seu desempenho de forma eficaz.
Usaremos a biblioteca Scikit-learn em Python para realizar esta divisão. Aqui está o código:

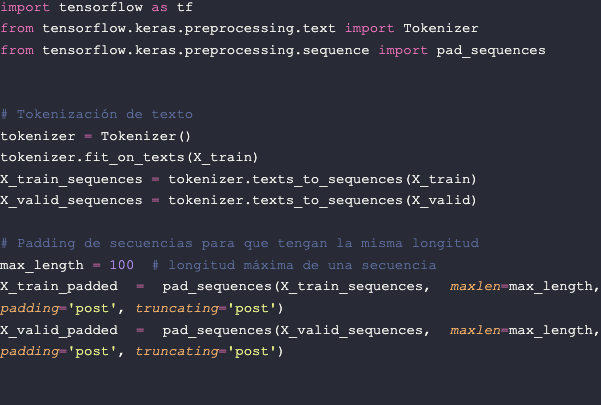
Tokenização de texto e de sequência Padding de sequência
Ao trabalhar com modelos de Processamento de Linguagem Natural (PNL) no contexto de Inteligência Artificial, é essencial preparar dados de texto de forma adequada. Duas das etapas essenciais neste processo são a tokenização de texto e o preenchimento de sequência. A seguir, exploraremos esses conceitos e sua importância na construção de modelos de IA para processamento de texto.
- Tokenización de Texto: é o processo de quebrar uma sequência de texto em unidades menores chamadas tokens, que geralmente são palavras individuais. A tokenização é essencial porque permite que a máquina compreenda e processe texto no nível de unidades significativas. Suponha que tenhamos a seguinte frase: “A inteligência artificial é fascinante”. A tokenização desta frase poderia gerar os seguintes tokens: ["O", "inteligência", "artificial", "é", "fascinante"].
- Padding de Sequências: Uma característica importante das redes neurais é que elas exigem que os dados de entrada tenham dimensões fixas. No entanto, as sequências de texto geralmente têm comprimentos variáveis. Para enfrentar esse desafio, usamos o Padding de Sequências, que consiste em ajustar o comprimento de todas as sequências de texto para que tenham o mesmo comprimento. Isto é conseguido adicionando tokens de preenchimento (geralmente representados como zeros) ao início ou ao final de sequências mais curtas. Essa uniformidade de comprimento é essencial para que as redes neurais processem dados de maneira eficaz. Suponha que temos duas frases: “O aprendizado de máquina é emocionante” e “Redes neurais”. Se definirmos um comprimento máximo de sequência de 5 tokens, a primeira frase será preenchida com tokens de preenchimento no final para atingir o comprimento desejado: ["O", "aprendizado", "automático", "é", "excitante"] . A segunda frase também seria preenchida de forma semelhante: ["Redes", "neurais", 0, 0, 0].
Esses processos de tokenização e padding nos permitem representar o texto de forma adequada ao processamento por uma rede neural, garantindo que todas as sequências tenham o mesmo comprimento. Para realizar este processo com Python usaremos a biblioteca TensorFlow:
Construindo e treinando o modelo de IA
Agora que preparamos nossos dados e os dividimos em conjuntos de treinamento e validação, prosseguiremos com a construção e treinamento de nosso modelo de IA. Neste caso, utilizaremos uma Rede Neural Recorrente (RNN) para realizar a classificação das mensagens em spam e ham.
1) Importando Bibliotecas e Criando o Modelo: essencial para construir e treinar nosso modelo.

2) TensorFlow sequencial: Criaremos um modelo de IA chamado Sequential no TensorFlow, que nos permite construir facilmente camadas uma após a outra.

3) Camada de Embedding: A camada do embedding é usada para converter palavras em números. Em outras palavras, ajuda o modelo a compreender o significado das palavras. vocab_size é o número total de palavras únicas em nosso conjunto de dados. embedding_dim é o número de números que representarão cada palavra. Esta camada é responsável por converter palavras em vetores de números.

4) Camada LSTM: Adicionamos uma camada LSTM (Long Short-Term Memory). Pense nesta camada como parte do modelo que pode lembrar informações importantes de sequências de palavras. units=64 significa que esta camada terá 64 “neurônios” que podem lembrar informações relevantes.

5) Camada Densa: Adicionamos uma camada densa que serve para fazer a classificação final entre spam e ham. 1 significa que esta camada possui uma única saída que é usada para classificação binária. Utilizamos a função de ativação sigmóide para que o modelo retorne um valor entre 0 e 1, onde valores próximos de 0 indicam presunto e valores próximos de 1 indicam spam.

6) Compilação de Modelo: Compilamos o modelo, o que significa que estamos configurando como ele será treinado. Usamos o otimizador adam, um algoritmo que ajuda o modelo a aprender com eficiência. Da mesma forma, usamos a perda (loss) binary_crossentropy pois fazemos uma classificação binária (duas classes: spam e ham). Também usamos precisão (accuracy) como uma métrica para ver quão bem o modelo funciona.

7) Treinamento de modelo: Avez que treinamos o modelo com nossos dados de treinamento. Epochs é o número de vezes que o modelo verá todo o nosso conjunto de treinamento. X_train_padded são as sequências de texto de treinamento com padding, y y_train são as tags correspondentes (spam ou ham). Também avaliamos o modelo em nossos dados de validação (conjunto de validação) para ver seu desempenho em dados que não foram vistos durante o treinamento.

Teste seu modelo
Agora vou mostrar como você pode usar o modelo treinado para prever se uma mensagem é spam ou não, fornecendo uma mensagem na forma de uma string. Aqui está um exemplo de código para fazer isso:
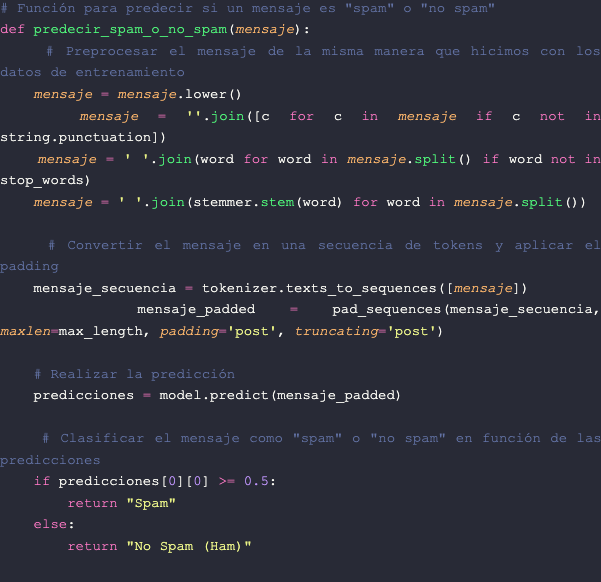
Criamos uma função chamada prever_spam_ou_não_spam que recebe uma mensagem como entrada. Dentro da função, pré-processamos a mensagem da mesma forma que fizemos com os dados de treinamento, convertendo-a para minúsculas, removendo sinais de pontuação, palavras irrelevantes e aplicando lematização ou stemming.
Então, convertemos a mensagem em uma sequência de tokens e aplicamos o padding para que tenha a mesma duração das sequências de treinamento. Por fim, usamos o modelo treinado para fazer uma previsão da mensagem e classificá-la como spam ou ham com base na previsão.
É importante entender como interpretar as métricas de desempenho de um modelo de classificação de spam. Duas métricas comuns são precisão (accuracy) e a perda (loss).
- A precisão indica a proporção de previsões corretas em relação ao total de previsões feitas pelo modelo. Um valor de precisão mais alto geralmente indica melhor desempenho.
- A perda é uma medida de quão bem as previsões do modelo se ajustam aos rótulos reais no conjunto de validação. Um valor de perda mais baixo geralmente indica melhor desempenho.
Você pode usar esta função prever_spam_ou_não_spam para testar qualquer mensagem desejada e ver se o modelo a classifica corretamente. Apenas certifique-se de ter treinado previamente o modelo conforme explicado nas etapas anteriores!


Conclusão
Em resumo, percorremos juntos as principais etapas para criar seu primeiro modelo de IA para classificar mensagens de spam, desde a obtenção de dados de exemplo até a construção e treinamento do modelo. No entanto, é importante lembrar que o desempenho do seu modelo depende muito da qualidade dos dados de treinamento e da escolha dos hiperparâmetros apropriados.
Vale ressaltar que, na classificação de spam, costuma haver um desequilíbrio significativo entre as classes spam e ham. Isso significa que há muito mais casos de spam do que de spam. Abordar este desequilíbrio é importante para evitar que o modelo seja tendencioso para a classe maioritária. Para fazer isso, podem ser usadas técnicas como reamostragem de classes minoritárias (aumento de dados de spam) ou ajuste de pesos de classe durante o treinamento do modelo. Essas estratégias ajudam o modelo a aprender igualmente com ambas as classes e a melhorar sua capacidade de identificar mensagens de spam.
É importante mencionar que o modelo apresentado neste artigo é um modelo básico desenhado para fins educacionais. Embora seja um bom ponto de partida, para um modelo mais completo e eficaz na classificação de mensagens de spam em um ambiente de produção, é necessário realizar uma preparação de dados mais exaustiva, considerar técnicas avançadas de processamento de linguagem natural e explorar diferentes arquiteturas de modelos. Além disso, atenção especial deve ser dada ao tratamento do desequilíbrio de classes, uma vez que em aplicações reais, a detecção precisa de mensagens de spam é essencial para a segurança e a experiência do usuário.
Portanto, ao se aventurar no mundo da IA e do aprendizado de máquina, lembre-se de que a experimentação e a iteração são fundamentais. Continue explorando, ajustando e melhorando seu modelo para obter resultados de classificação de spam ainda mais precisos! Com dedicação e prática, você será capaz de construir modelos de IA cada vez mais eficazes e úteis em diversas aplicações. Boa sorte em sua jornada para a criação de Inteligência Artificial!
Se quiser consultar o modelo realizado, pode fazê-lo aqui.
A Revelo Content Network acolhe todas as raças, etnias, nacionalidades, credos, gêneros, orientações, pontos de vista e ideologias, desde que promovam diversidade, equidade, inclusão e crescimento na carreira dos profissionais de tecnologia.