Concurrency: parte 1

A simultaneidade (concurrency) é uma coisa difícil de abordar na programação porque o perfil dos escritores de código pode variar de graduados formais em ciência da computação a iniciantes que fizeram um bootcamp de código.
O engraçado é que, para ambos os casos, a simultaneidade pode ser algo fácil de entender, mas difícil de implementar. Esta série de artigos procura dar uma introdução muito completa aos diferentes sistemas com os quais interagimos no nosso dia a dia, bem como algumas implementações utilizando Linux, Node.js, Ruby e Python. Esta série é ideal se:
- Você nunca leu sobre.
- Você deseja atualizar os conceitos.
- Você é usuário de algumas destas tecnologias?
- Você quer entender completamente a simultaneidade.
Este artigo em particular visa marcar os precedentes que levam a uma explicação e compreensão muito melhor da concorrência. Vamos começar com Processos e Threads e suas implementações Ruby e Python.
Processos
Para entender completamente a simultaneidade, devemos primeiro entender alguns conceitos básicos de sistemas operacionais. Para isso usaremos o Linux (embora tudo visto neste artigo se aplique a sistemas Unix), começando pelos processos.
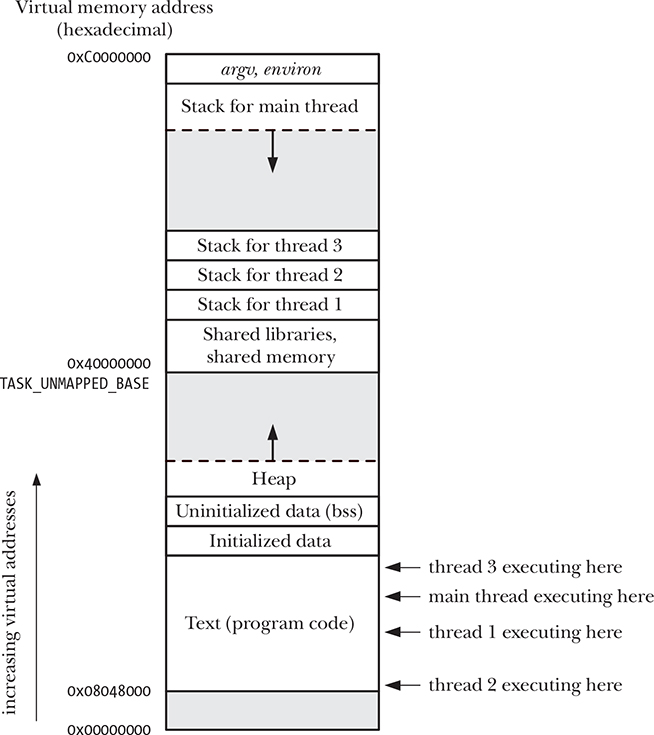
Processos são basicamente programas em execução. No Linux, cada processo contém espaço de memória, tempo de processador e recursos de entrada/saída (E/S), que podem ser gerenciados e monitorados.
Programas, por outro lado, são arquivos que contêm informações sobre como um processo será construído em tempo de execução. Basicamente, é o código que você escreve em Node.js, Python, Ruby, etc., para que possamos entender a importância dos processos: são todos os programas que seu sistema operacional executa quando você liga seu computador!
Cada processo é logicamente dividido pelos seguintes segmentos:
- Texto: instruções do programa.
- Dados: variáveis estáticas usadas pelo programa.
- Heap: área de onde um programa pode alocar memória extra (além do espaço de memória alocado a ele).
- Stack: espaço de memória que aumenta e diminui à medida que as funções são chamadas. Ele é usado para alocar armazenamento para variáveis locais e chamadas de função com informações vinculadas.
Ao chamar o seguinte comando podemos monitorar os processos em execução: ps aux

Como o escopo deste artigo não é analisar os processos em profundidade, descreveremos apenas alguns dos sinalizadores do comando ps aux.
- PID Identificador exclusivo do processo. Será muito útil durante o resto do artigo.
- %CPU Porcentagem de CPU que o processo está usando.
- %MEM Porcentagem de memória real usada pelo processo.
- TIME Tempo de CPU usado pelo processo
- Comando Ação que chama o processo junto com seus argumentos.
O seguinte programa de Python nos ajudará a entender o conceito de processo:
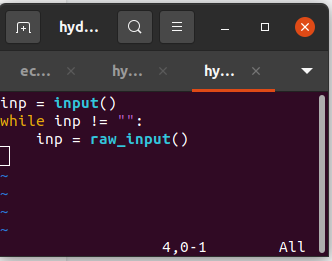
Uma vez que o programa foi executado em segundo plano com o seguinte comando (observe o & no final): python wait_input.py &

…vamos notar que o PID é 14686. O %CPU é 0.0. %MEM 0.0 TIME 0.0 e o comando python3 wait_input.py.
Neste caso, o programa não utilizou nenhum recurso porque está basicamente aguardando valores de entrada em: raw_input().
Agora que conhecemos o PID do processo, podemos gerenciá-lo. Nesse caso, pararemos o processo executando: kill -9 14686.
É muito importante observar que todo processo possui pelo menos uma thread por padrão. Uma thread é um contexto de execução dentro de um processo. Cada thread tem seu próprio stack e contexto de CPU, mas opera dentro do espaço de endereçamento alocado ao processo que o contém.
Cada processo é capaz de criar múltiplas threads para serem executadas de maneira quase paralela. 'Quasi-paralelo' é indicado quando uma thread é executado em uma única máquina de CPU. Considerando que arquiteturas de hardware recentes já possuem múltiplas CPUs e múltiplos núcleos (multicore), as threads podem ser executadas em paralelo nestes tipos de máquinas. Embora essa decisão seja feita na máquina virtual das linguagens (pelo menos aquelas que usam máquinas virtuais) e pelo sistema operacional.
Uma parte importante para entender dentro do mundo da simultaneidade é o conceito de multiprocessamento, mas veremos isso em outro artigo. Em seguida, vamos expandir ainda mais o conceito de threads.
Tópicos
"Thread é um processo como processo é uma máquina" - Andrew S. Tanenbaum.
Vamos tomar como exemplo quatro processos rodando no Linux. Cada um tem suas próprias informações descritas acima: espaço de memória, stack, etc. Eles não compartilham nada entre si, exceto que podem se comunicar entre si por meio de primitivas do sistema operacional, como: semáforos, monitores, mensagens, etc. Por outro lado, temos um processo com várias threads.
Cada thread:
- Se executa estritamente sequencialmente (em uma única máquina de CPU) assim como os processos.
- Você pode criar threads filhos.
- Você pode se trancar.
- Dentro do mesmo processo, uma thread pode ser executada, desde que a outra esteja bloqueada.
Poderíamos dizer que uma thread é um processo rodando em um processo, pois tem quase o mesmo conceito de design (como vimos no parágrafo anterior). Daí a citação de Tanenbaum.
Tópicos no Linux
O Linux usa threads POSIX ou PThreads, um padrão proposto pelo IEEE para escrever programas de thread portáteis. Isso significa que o kernel do Linux usa a API PThreads para criar programas que usam vários threads. Se você quiser se aprofundar no mundo dos threads do Linux, acesse este link:
Se executarmos o comando top -H, podemos ver a lista de processos em execução e o número total de threads atuais no sistema:

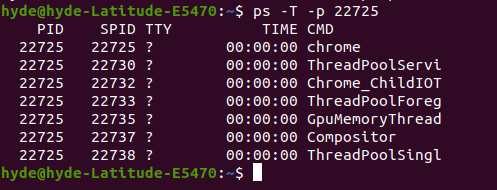
Comumente, os programas do usuário, como o Google Chrome, terão vários threads em execução. Então, se digitarmos o comando ps -T -p 22725 onde 22725 é o PID do chrome, podemos ver os vários threads em execução:
Agora que vimos os diferentes casos de uso de threads no exemplo mais comum (sistemas operativo), podemos ver como criar threads em Ruby e Python.
Tópicos em Ruby
Podemos pensar que o uso de threads nos ajudará a reduzir o desempenho de um programa. Em muitos casos é assim, em outros não. Depende do problema a ser resolvido e do idioma.
Em Ruby, a maneira de criar threads é usando a classe Thread, embutida no Ruby, conforme mostrado abaixo:
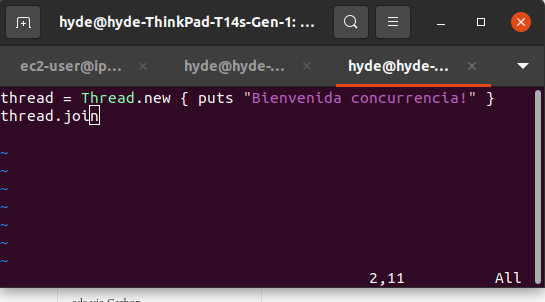
Essa classe nos permite executar o código usando o paradigma multithreading (algo semelhante ao que acontece com o Linux). Podemos aplicar um pouco a ideia de dividir e conquistar, então o caso de uso a seguir é perfeito.
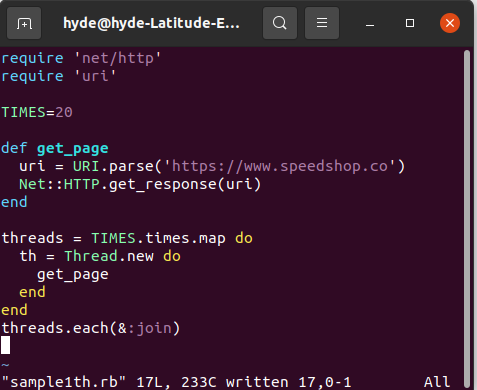
Caso de uso: várias chamadas para consultar uma página da web
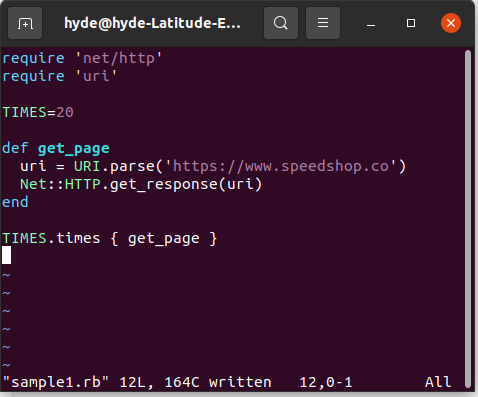
Neste caso de uso, podemos ver que é ideal para Ruby, pois é limitado por E/S. Esse conceito refere-se a longos tempos limite devido a partes do código aguardando a conclusão das operações de entrada ou saída. Esses tempos geralmente são de espera pelo sistema de arquivos, comunicação de rede, entre outros.
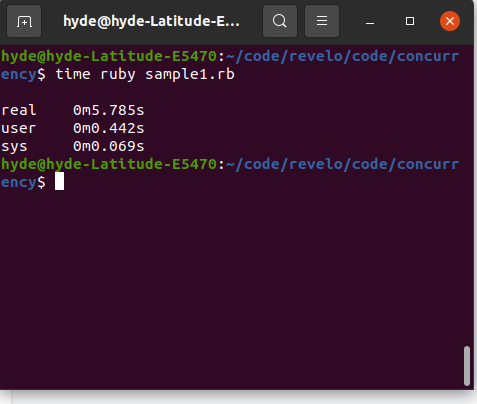
Mas é realmente mais eficiente? Para resolver esta questão temos que rodar o programa novamente, usando threads e não threads.
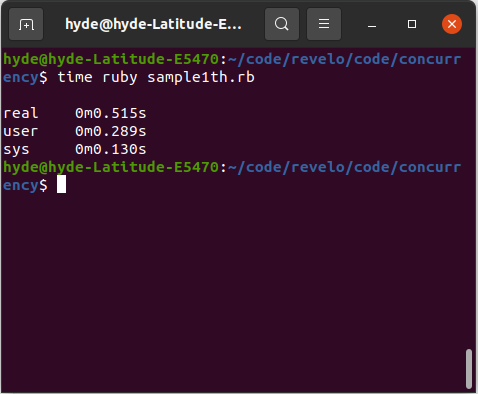
Nota a diferença? Pode não ser tanto quanto esperávamos (é 5 vezes melhor e temos 20 threads em vez de um) e isso se deve a um mecanismo que a máquina virtual Ruby MRI chamou: GVL ou GIL, um mecanismo para sincronizar threads que Ruby usa , assim como outras linguagens dinâmicas como Python (quando rodando em CPython).
Apesar de poder criar várias threads de execução em um programa, esse mecanismo executa uma thread por vez, mesmo que o computador seja multicore.
Existe uma maneira de determinar o tempo de melhoria quando um código é implementado usando threads (em Ruby).
Lei de Amdahl:
Amdahl percebeu que a velocidade que você obtém ao adicionar paralelismo adicional está relacionada a uma proporção do tempo de execução que pode ser feita em paralelo. Essa regra é simples: 1 / (1 - p + p/s) onde p é a porcentagem da tarefa que pode ser feita em paralelo e s é o fator de velocidade da parte dessa tarefa que obtém a melhora nos resultados. O seguinte é um gráfico popular que representa esta lei:
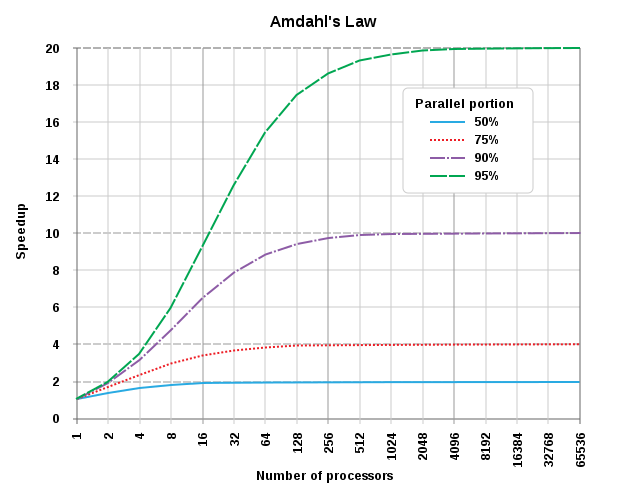
Podemos ver que quanto maior a porcentagem da tarefa é trabalhada em paralelo, melhor sua velocidade dependendo do número de processadores disponíveis.
No exemplo que colocamos podemos notar que 50% da atividade pode ser realizada em paralelo (a chamada para a página). Enquanto o número de threads (ou processadores no contexto da lei de Amdahl) é 20.
p = 0,85
s = 20
1 / (1 - 0,5 + 0,5/20) = 5,19
Tópicos em Python
As abstrações são ferramentas superpoderosas da mente humana. No caso de Threads (no contexto de programação) é uma abstração que, uma vez compreendida, nos ajuda a aplicá-la em múltiplas linguagens de programação sem redefinir sua definição. Nesta ocasião, a única coisa que muda, em relação ao que vimos até agora, é a implementação e as particularidades da linguagem.
Em Python, as bibliotecas Threading e Asyncio são usadas para implementar o conceito de threads. Neste artigo falaremos sobre Threading, enquanto nos próximos posts desta série abordaremos o Asyncio.
Ao usar a biblioteca Threading teremos algo parecido com Ruby: threads rodando uma de cada vez ou, como deixamos claro anteriormente, quase paralelas, mesmo que tenhamos threads rodando em um computador multicore. Dada a implementação do Python no CPython, as interações com o GIL (Global Interpreter Lock, muito semelhante ao que vimos em ruby com GVL) limitam o Thread a rodar uma vez.
No entanto, algo único sobre a biblioteca Threading é que o sistema operacional decide fazer essa alternância entre as atividades, em vez do Python. Isso é chamado de multitarefa preemptiva, pois o sistema operacional fornece os recursos necessários para a thread e é quem realiza a alternância de tarefas.
Como vimos na seção sobre encadeamento com Ruby, os programas que se beneficiam do uso de encadeamentos para melhorar o desempenho são aqueles que passam muito tempo esperando por eventos externos.
Vamos ver o mesmo exemplo de implementação de uma página web em Python (CPython).
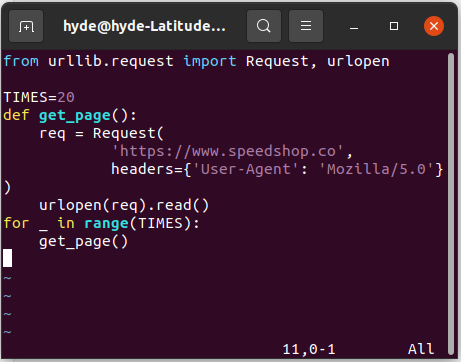
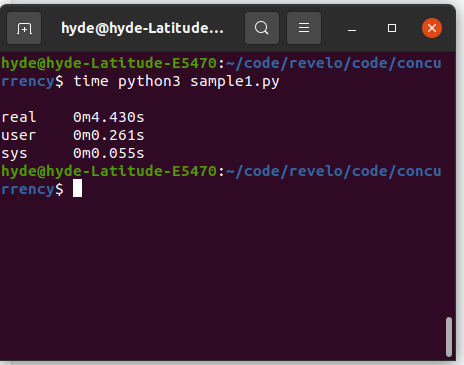
Agora usando 20 threads de execução:
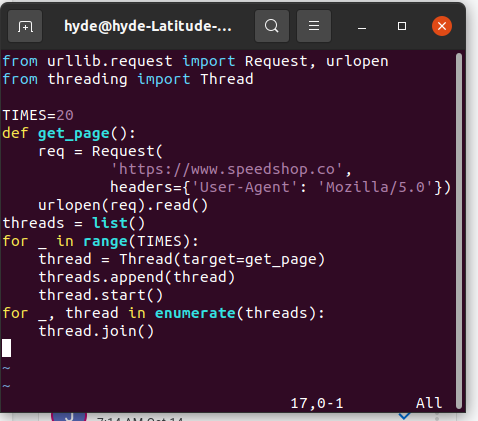
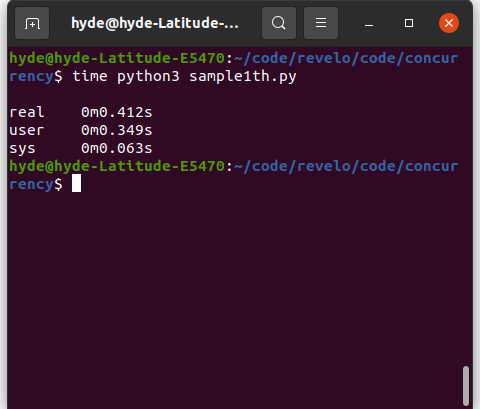
Como podemos ver, a funcionalidade do GIL torna o código não 20 vezes mais rápido. No entanto, há uma melhoria notável na reescrita do script python em threads.
Conclusão
Cobrimos o conhecimento básico para entender a simultaneidade: processos e threads, bem como diferentes exemplos, casos de uso e implementações mais conhecidas. Nos próximos posts, veremos novas formas de implementar threads em Ruby (reatores) e Python (assíncrono), além de outras linguagens como Node.js e técnicas como multiprocessamento.