Analisando conversas do WhatsApp usando Python (parte 1)


A inspiração para esta história começa com um desafio: "Eu te amo mais". Tal afirmação merece ser apoiada por fatos e, sendo eu mesmo um cientista de dados, decidi parametrizar nosso relacionamento para que não haja dúvida de quem ama mais quem.
A seguir, compartilho com vocês uma pequena parte dessa aventura: a análise de uma conversa no WhatsApp. Um projeto que nos levará da exportação de um arquivo de texto para responder a perguntas como: quem responde mais rápido?, quem usa emojis de amor com mais frequência?, quem inicia conversas? e, esperançosamente, obter os argumentos necessários para responder à grande questão: quem ama mais quem?
Para seguir este tutorial, você precisará de conhecimentos básicos de Python e Regex. Se você não é um especialista em Regex, não se preocupe! Veremos o básico na etapa 3.
Esta série de blog-tutoriais consistirá em 2 partes:
- Importar e estruturar dados com Pandas e Regex
- Análise exploratória com Pandas e Seaborn
Nesta primeira entrada, aprenderemos como importar conversas do WhatsApp de nosso smartphone para um objeto DataFrame em Python.
Passo 1- Importe a conversa para um .txt
Vamos começar abrindo nosso aplicativo WhatsApp e selecionando a conversa de interesse. Em seguida, clique no menu no canto superior direito e selecione a opção "mais".
Em seguida, vamos selecionar a opção de exportar o chat e selecionar a opção de salvar sem mídia. Por fim, vamos escolher o método que queremos para fazer o backup das informações e pronto. Eu escolhi a opção de salvar o arquivo diretamente no meu Google Drive. Uma vez finalizado este processo, notamos que possui um arquivo .txt com toda a conversa dentro. Esse arquivo é exatamente o que precisamos para começar. Vamos salvar o arquivo no disco local, abrir seu Python IDE favorito e começar a trabalhar!
Passo 2 - Leia o arquivo de texto com Python
Começaremos carregando as bibliotecas que precisaremos: Re e Pandas.
import pandas as pd
import reDurante a execução do tutorial utilizarei as versões:
- 2.2.1 do Re
- Panda 1.4.2
Para aqueles que nunca trabalharam com essas bibliotecas antes, Re é o mecanismo Regex integrado do Python. Regex, ou expressões regulares, são uma coleção de caracteres e operadores que nos permitem procurar padrões no texto. Por exemplo, podemos usar o Regex para encontrar padrões genéricos de números, datas, nomes ou similares em um documento. Neste projeto, usaremos o Regex para converter um arquivo de texto em dados estruturados. Além disso, contaremos com o Pandas para manipular e realizar análises básicas em nossos dados estruturados.
Depois que as bibliotecas forem importadas, usaremos uma instrução with para ler nosso arquivo de texto e fechá-lo quando terminar. Desta vez, estou executando o código python no mesmo diretório onde tenho meu .txt, então não há necessidade de declarar o caminho completo para o arquivo.
with open('chat.txt') as f:
chat_crudo = f.read()Usando o método .read(), despejamos todo o conteúdo do nosso arquivo de texto na variável raw_chat. Se você verificar o tipo da variável, notará que é uma str (possivelmente muito longa). No meu caso particular, raw_chat contém 1.885.419 caracteres! Você também pode verificar usando len(chat_raw).
Em seguida, eu recomendaria imprimir alguns caracteres para se familiarizar com a estrutura da conversa.
Agora que você salvou sua conversa como uma variável no Python, devemos analisá-la facilmente, certo? A resposta é: claro! Logo após analisar ou processar os dados.
Embora um str por si só já possa nos fornecer algumas informações importantes sobre a conversa, como o número de caracteres ou o número de vezes que uma palavra aparece no texto, a realidade é que um str não é o formato adequado para responder às nossas perguntas . Para analisá-los adequadamente, devemos passá-los para um formato de dados estruturados. Por exemplo, para uma tabela onde cada linha é uma mensagem e cada linha tem colunas como a data, o remetente e o conteúdo da mensagem como ela é.
Passo 3 - Analisando a conversa usando Regex
Aqui está um trecho da conversa:

Claramente, existem padrões na forma como os dados foram salvos. Por exemplo, posso ver que cada linha começa com a data, depois o remetente e a mensagem. Também posso ver que a data sempre vem no formato mm/dd/aa e a hora no formato am/pm, mais tudo vem entre colchetes. Para extrair todas as informações, você precisa gerar um padrão como '[data em mm/dd/aa e hora em am/pm]' e pegar todas as partes do texto que correspondam a esse padrão. É exatamente disso que trata o Regex. Só precisamos saber como alimentar esse padrão para o mecanismo Regex.
Para ter uma ideia de como o Regex funciona, recomendo começar com essas dicas. Mantenha-o à mão, será útil mais tarde. Além de um portal interativo para testar o que aprendemos sobre Regex, usarei o seguinte para o restante do tutorial: https://regex101.com/
Uma vez no regex101, é importante garantir que configuramos o uso correto do mecanismo Regex em Python. Embora o Regex seja independente de idioma, existem algumas diferenças nas implementações específicas em diferentes idiomas. Como trabalharemos com Python, vamos configurar esta ferramenta clicando na caixa de seleção a seguir.
Agora é só colar um segmento de nossa conversa no campo Test String e testar nossos padrões.
O primeiro padrão com o qual trabalharemos é o padrão de data. Como mencionamos anteriormente, nossas datas vêm como 'mm/dd/yy'. Se Regex reconhecesse datas, poderia ser tão simples quanto isso. No entanto, nos limitamos a caracteres como letras, números e espaços. Se fôssemos generalizar o padrão de datas, diríamos algo como:
número do suporte número do número da diagonal número do número da diagonal. Revendo as dicas, podemos ver que existe precisamente um operador no Regex para capturar números. Podemos gerar esse padrão genérico da seguinte maneira:
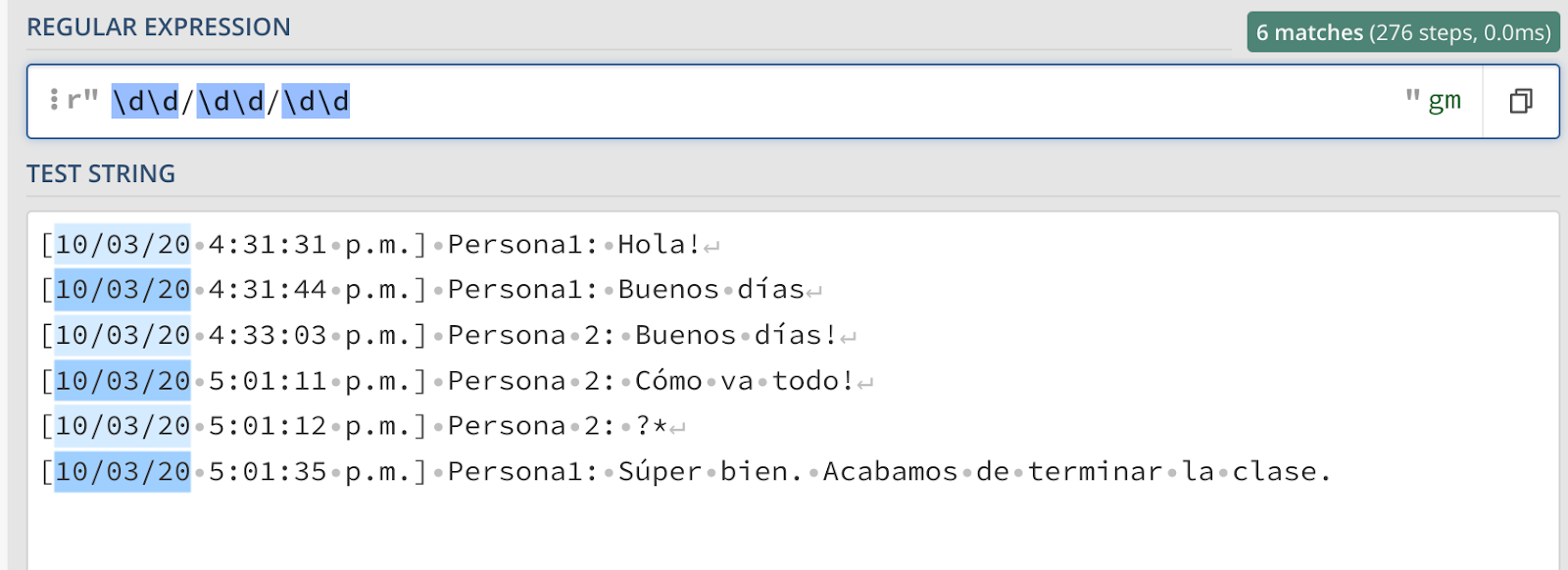
Usando “\d” acabamos de corresponder a qualquer dígito. Usando “\d\d” combinamos qualquer dígito seguido por outro dígito. A ferramenta regex101 nos mostra graficamente quais padrões seriam capturados.
Agora, como poderíamos capturar o tempo? O padrão deve ser generalizado em algo como: número dois pontos número dois dois pontos número espaço p ponto m ponto. Em Regex, isso ficaria assim:
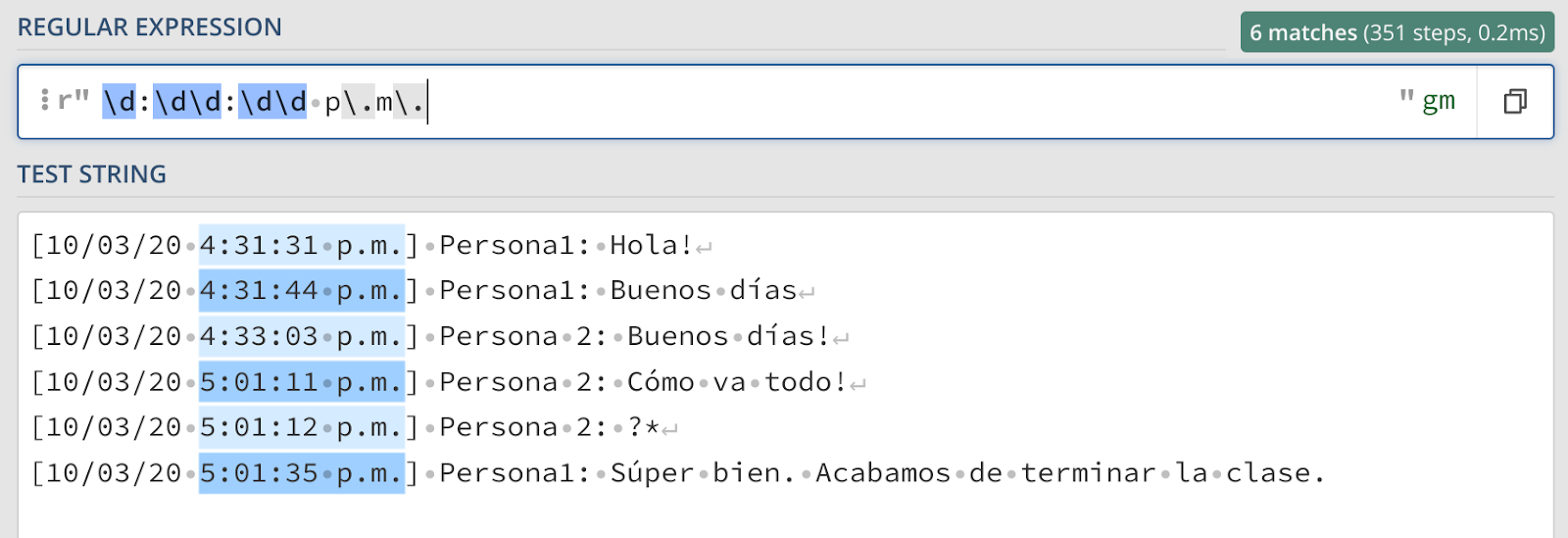
Observe como os pontos não são capturados diretamente com um “.”, mas são escapados “\.”. Se você revisar as dicas, verá que o “.” é um caractere especial e representa qualquer detalhe, exceto uma nova linha. Para capturar especificamente um ponto, você precisa passar um “\” como se fosse capturar literalmente um ponto.
Agora vamos usar grupos para capturar a data e hora com parênteses da seguinte forma:
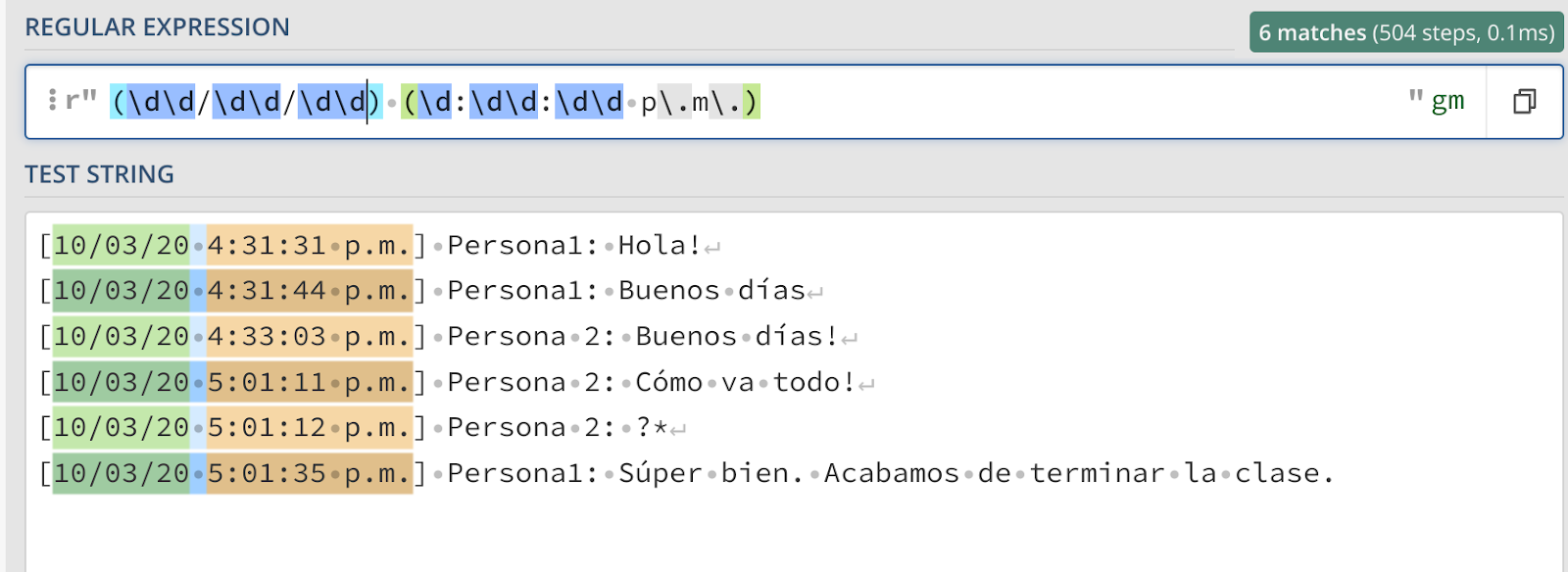
Agora podemos ver que dois grupos separados são capturados, um verde e um laranja. Verde corresponde ao primeiro conjunto de parênteses e laranja ao segundo conjunto de parênteses. Já estamos analisando nosso documento!
Uma maneira mais elegante de trabalhar com o padrão \d\d é adicionar um quantificador. Isso pode ser especialmente útil se houver possibilidade de variações no formato. Por exemplo, em vez de 07 de 10, veja 7 de 10. Isso quebraria nosso padrão. Para mitigar isso, usaremos o quantificador exato declarando que esperamos ver 1 ou 2 dígitos da seguinte forma:
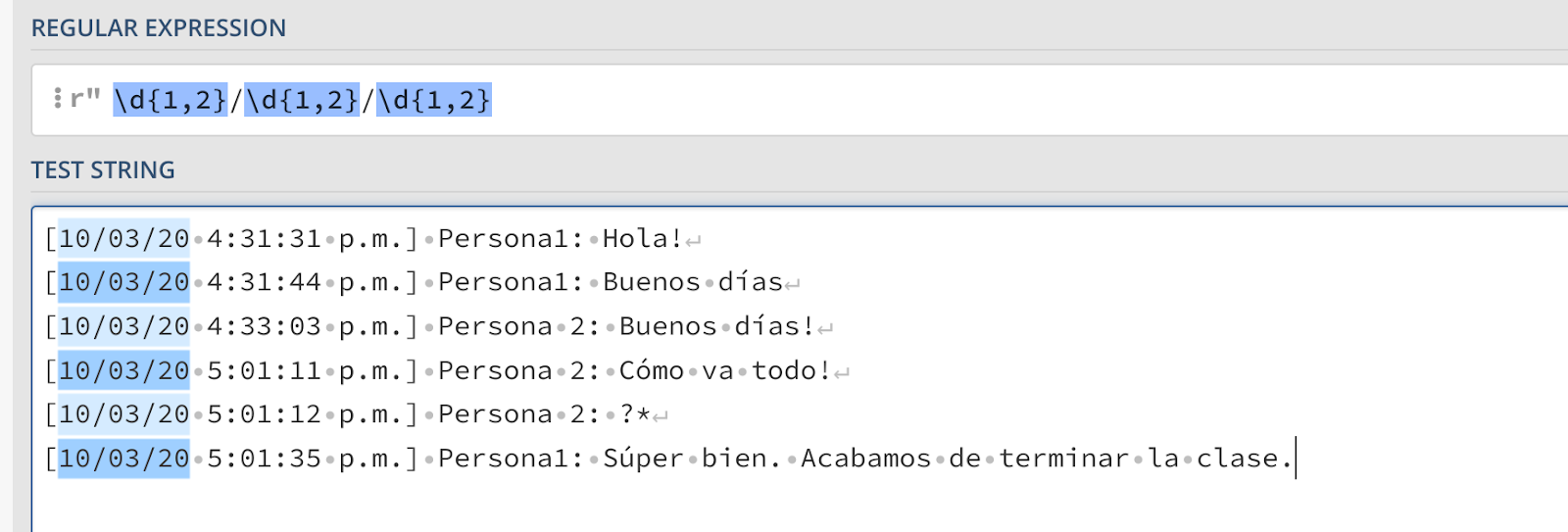
O próximo elemento é o nome do emissor. No meu caso, posso ver Person1 e Person 2 e posso tentar capturar esses nomes explicitamente ou tentar generalizar ainda mais. Como conheço a estrutura do meu texto, poderia dizer algo como: Depois de uma data segue uma hora, depois da hora ela capta tudo até antes do ":". Para isso, usaremos um quantificador preguiçoso, ou seja, ele irá capturar o menor número de caracteres entre a data, a hora e os dois pontos. Isso se parece com isso:
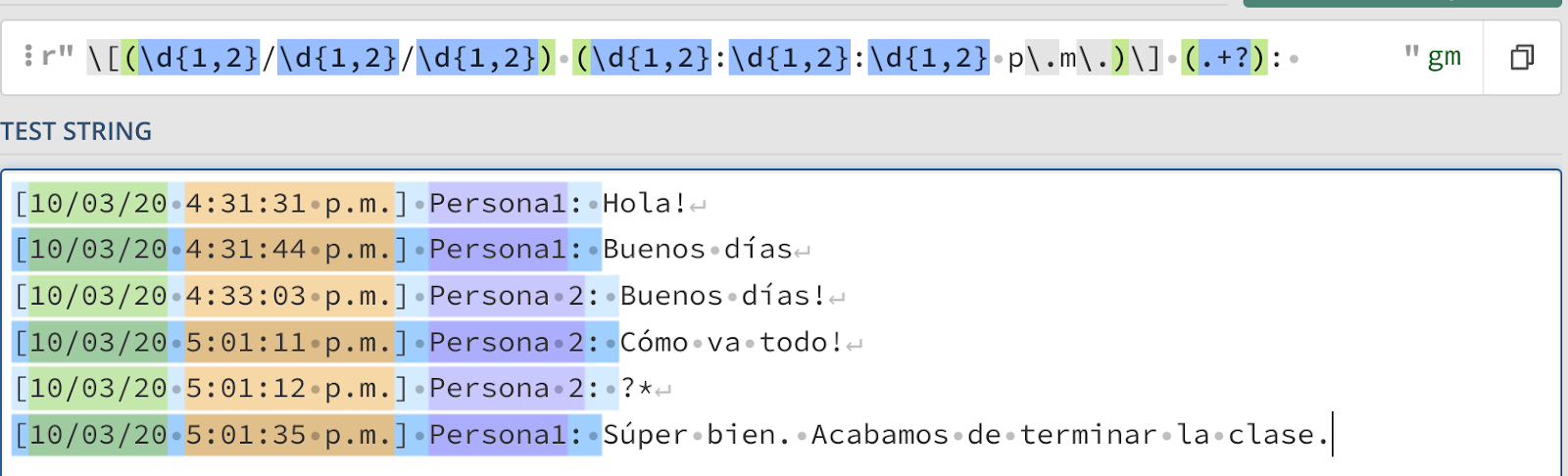
Observe como desta vez incluí os colchetes. No entanto, uma vez que estes são especiais em Regex, também exigem que um "\" seja passado antes de capturar literalmente como colchetes.
Antes de capturar o último componente de interesse, a mensagem, é importante antecipar um possível problema. O que acontecerá quando em vez de "p.m." Vamos ver nosso tempo em "a.m."? No Regex, podemos definir opções dentro de um padrão, de modo que, em vez de capturar literalmente "p.m.", podemos especificar literalmente a captura de "p.m." ou “am” usando os colchetes e notação de tubo da seguinte forma:
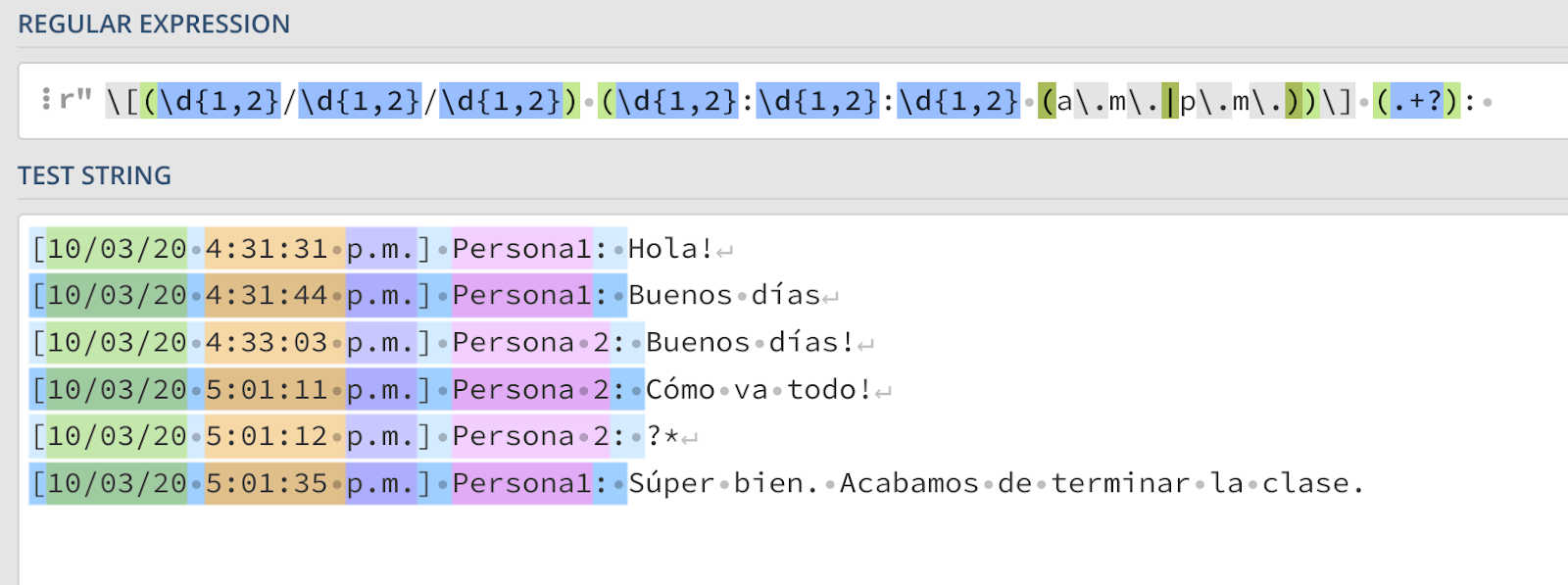
Resta apenas capturar a última parte: a mensagem. Este talvez seja o mais fácil: basta solicitar tudo o que segue o remetente até a próxima quebra de linha, algo que podemos fazer com um ponto e um quantificador.
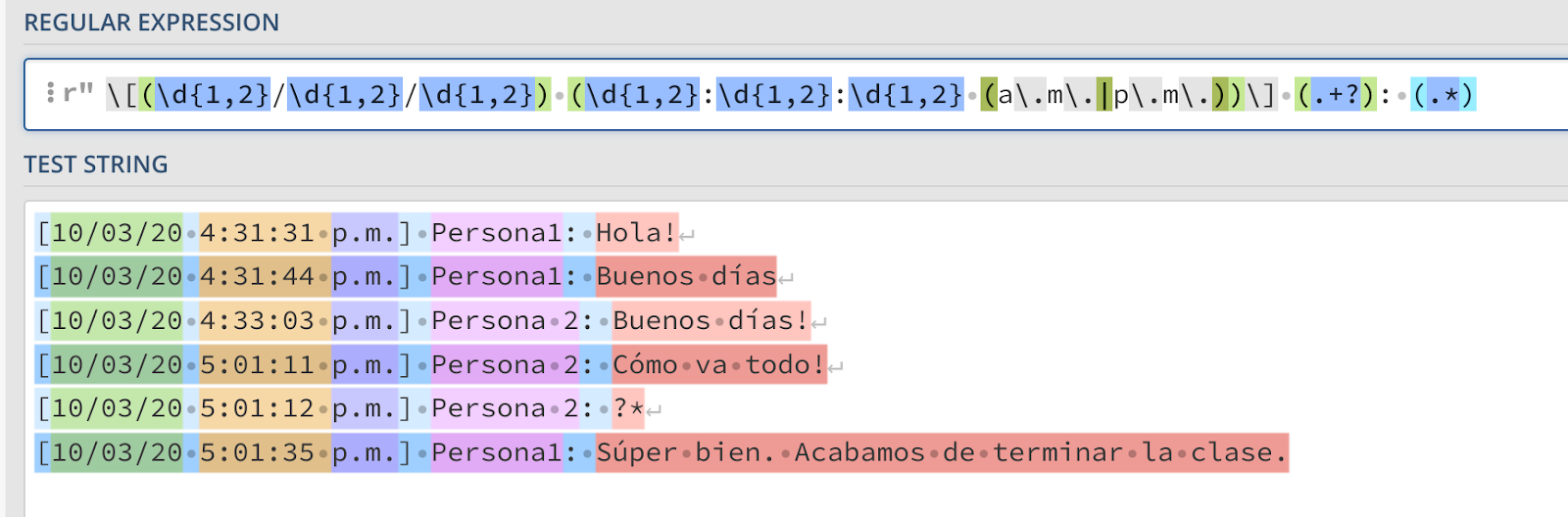
Pronto! Já temos um padrão que pode segmentar minha conversa em partes individuais. Agora que terminei de testá-lo no regex101, é hora de voltar ao Python para fazer a análise.
Observação: o padrão que mostro teria problemas para ler mensagens com várias linhas. Para os fins deste tutorial, vamos nos ater a esse padrão. Se você quiser capturar mensagens multilinhas, recomendo procurar lookaheads para capturar tudo até que o início do padrão seja repetido.
Etapa 4 - Converter a conversa em um DataFrame
Para aplicar nosso padrão ao texto e depois convertê-lo em uma tabela, devemos retornar ao Python.
patron = re.compile(r'\[(\d{1,2}/\d{1,2}/\d{1,2}) (\d{1,2}:\d{1,2}:\d{1,2} (a.m.|p.m.))\] (.+?): (.*)')
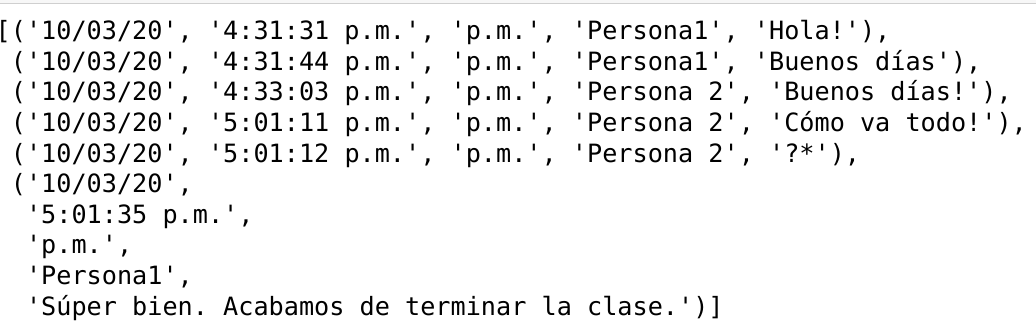
coincidencias = patron.findall(chat_crudo)Usamos re.compile() para converter uma string Python em um padrão Regex. Em seguida, usamos o método .findall() no padrão e passamos nosso chat como parâmetro. Findall pegará todos os grupos que colocamos entre parênteses e os converterá em uma lista de tuplas onde teremos cada pedaço de string que corresponde ao padrão. Quando imprimo correspondências, vejo:
Agora que dividimos a conversa, podemos passá-la para um formato tabular como um DataFrame usando:
chat_procesado = pd.DataFrame(coincidencias, columns = ['Fecha', 'Hora', 'ampm', 'Emisor', 'Mensaje'])Ao imprimir chat_processed vemos:

Excelente! Agora que estruturamos nossa conversa, fazer a análise ficará muito mais fácil e nos dará a flexibilidade necessária para responder às perguntas.
Em meu próximo artigo, veremos ferramentas de gráficos, métricas e algumas ideias de análise para responder à grande pergunta: quem ama mais quem?